Physicians shouldn’t have to wait for resources that help their patients access treatment.
At Impiricus, our mission is simple: deliver the right clinical resources to physicians in real time, exactly when they need them. As a result, patients get on treatment faster.
Recent advancements in AI are bringing that goal closer to reality.
We recently ran a pilot inside Ascend, our agentic AI delivery platform, testing an alternative generation of AI models called diffusion-based language models (dLLMs). The results show how emerging AI architectures can dramatically improve the speed and responsiveness of physician support systems.
And when the system moves faster, physicians and patients benefit.
Testing the Next Generation of AI Models
At the core of these systems is our proprietary margin-optimized embeddings reinforcement learning engine. In simple terms, this technology helps the platform understand what physicians are asking for, match those needs to the most relevant clinical or pharmaceutical resources, and continuously improve those recommendations over time.
“Margin-optimized” refers to how the system prioritizes the highest-impact matches between physician needs and available resources, ensuring that the most useful information surfaces first. Instead of treating every message or piece of content equally, the system learns which responses are most valuable in real clinical moments.
This approach allows Ascend to act as an intelligent Virtual Coordinator, filtering out noise and delivering the right information to physicians when it matters most.
To explore the next wave of AI capabilities, we recently ran a pilot using Mercury-2, the diffusion language model developed by Inception Labs. In this test, we replaced the traditional GPT-based model in our stack while keeping our core proprietary algorithms unchanged.
The performance improvements were immediate.
Key results from the pilot:
- ~95% peak accuracy, consistent with our existing stack
- Convergence in significantly fewer rounds
- 3–4x faster overall runtime
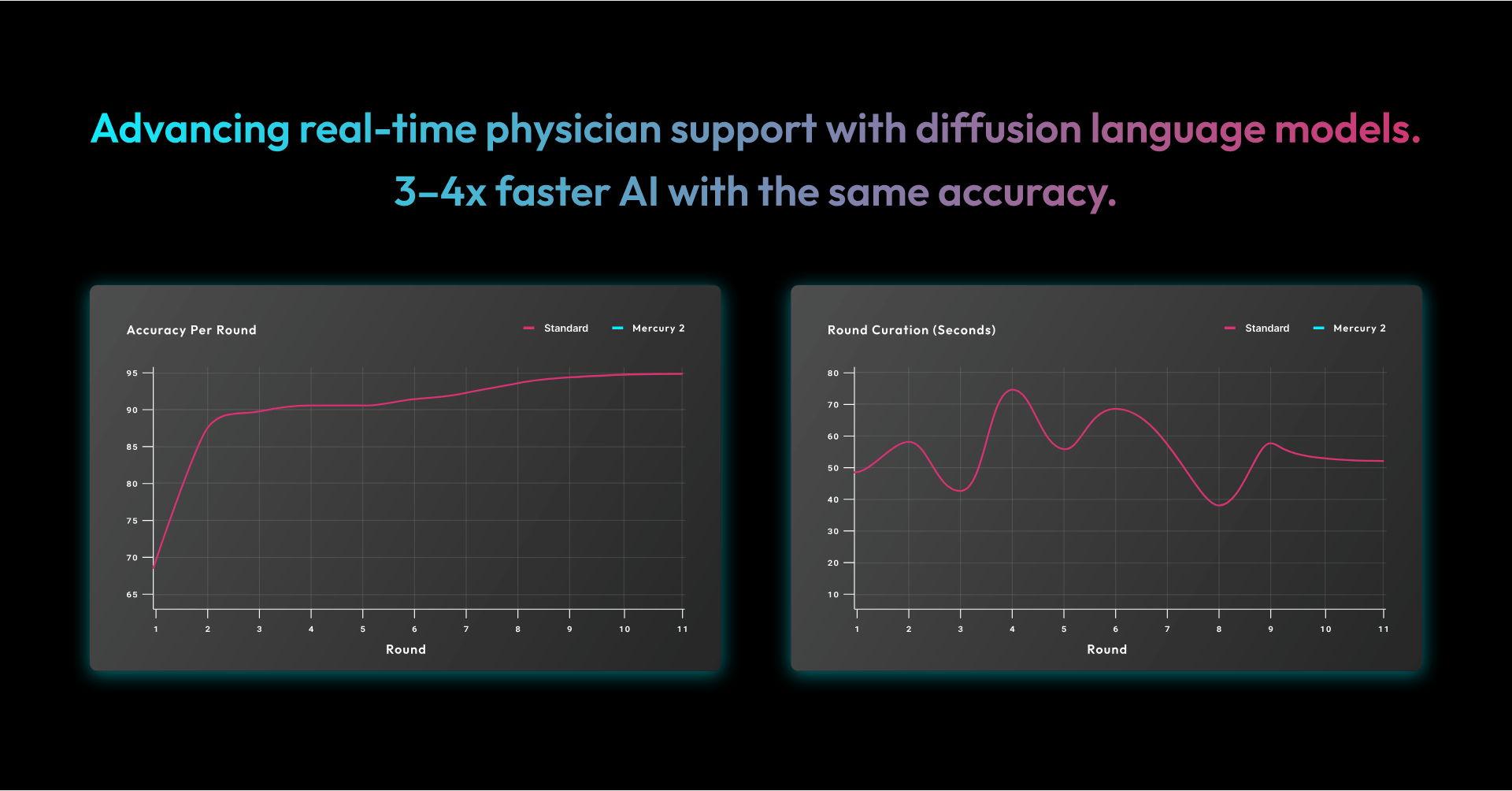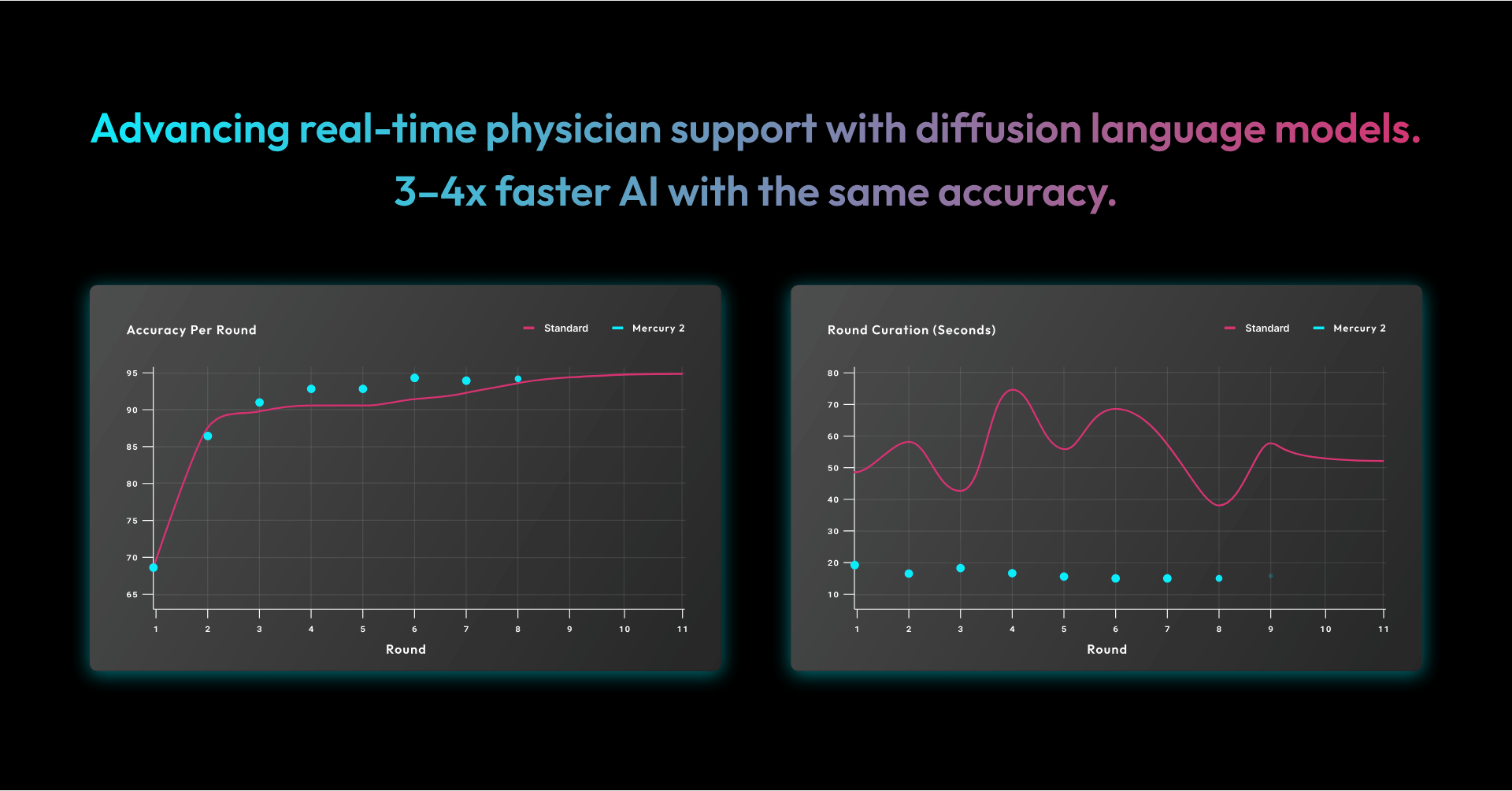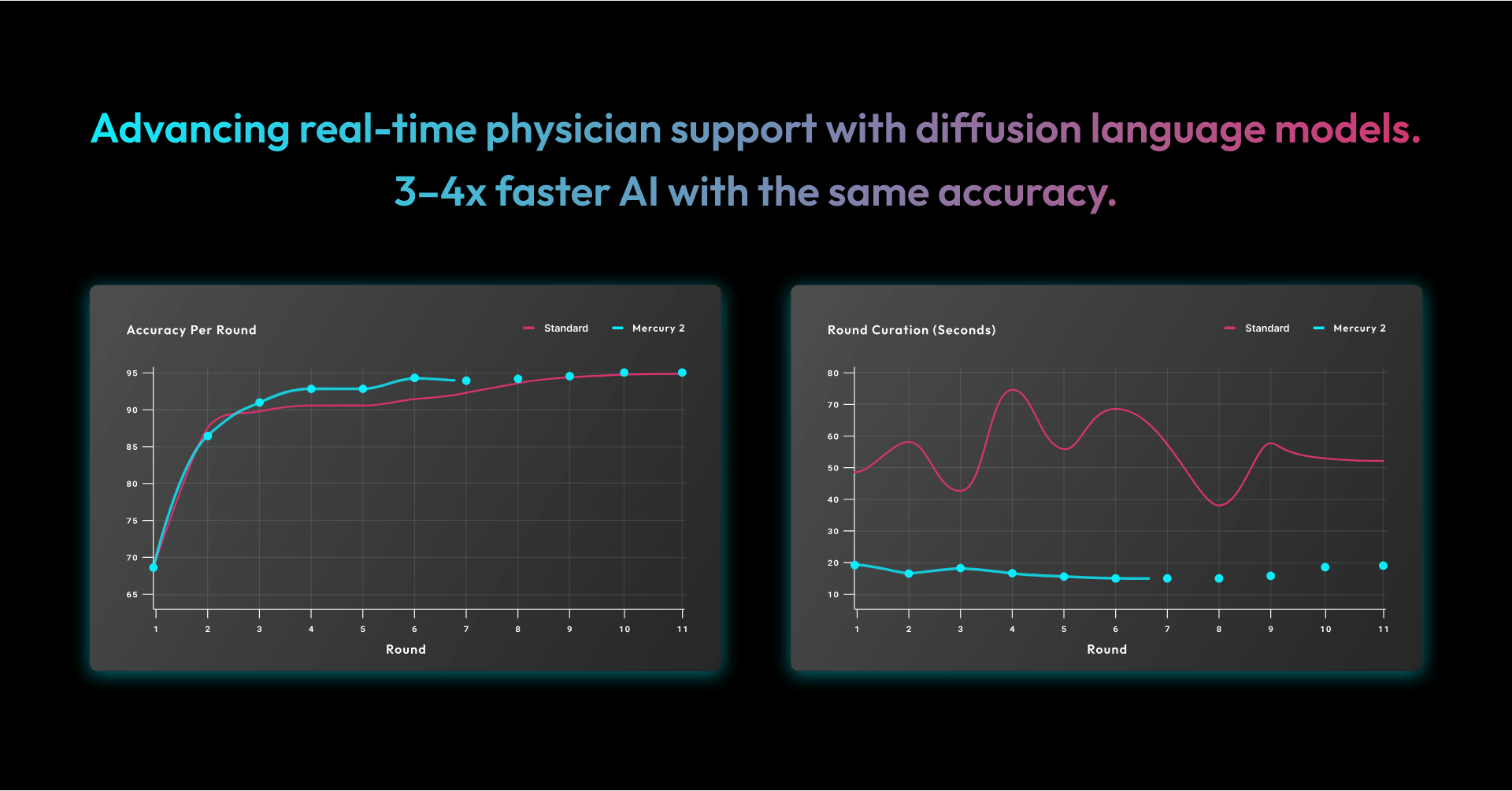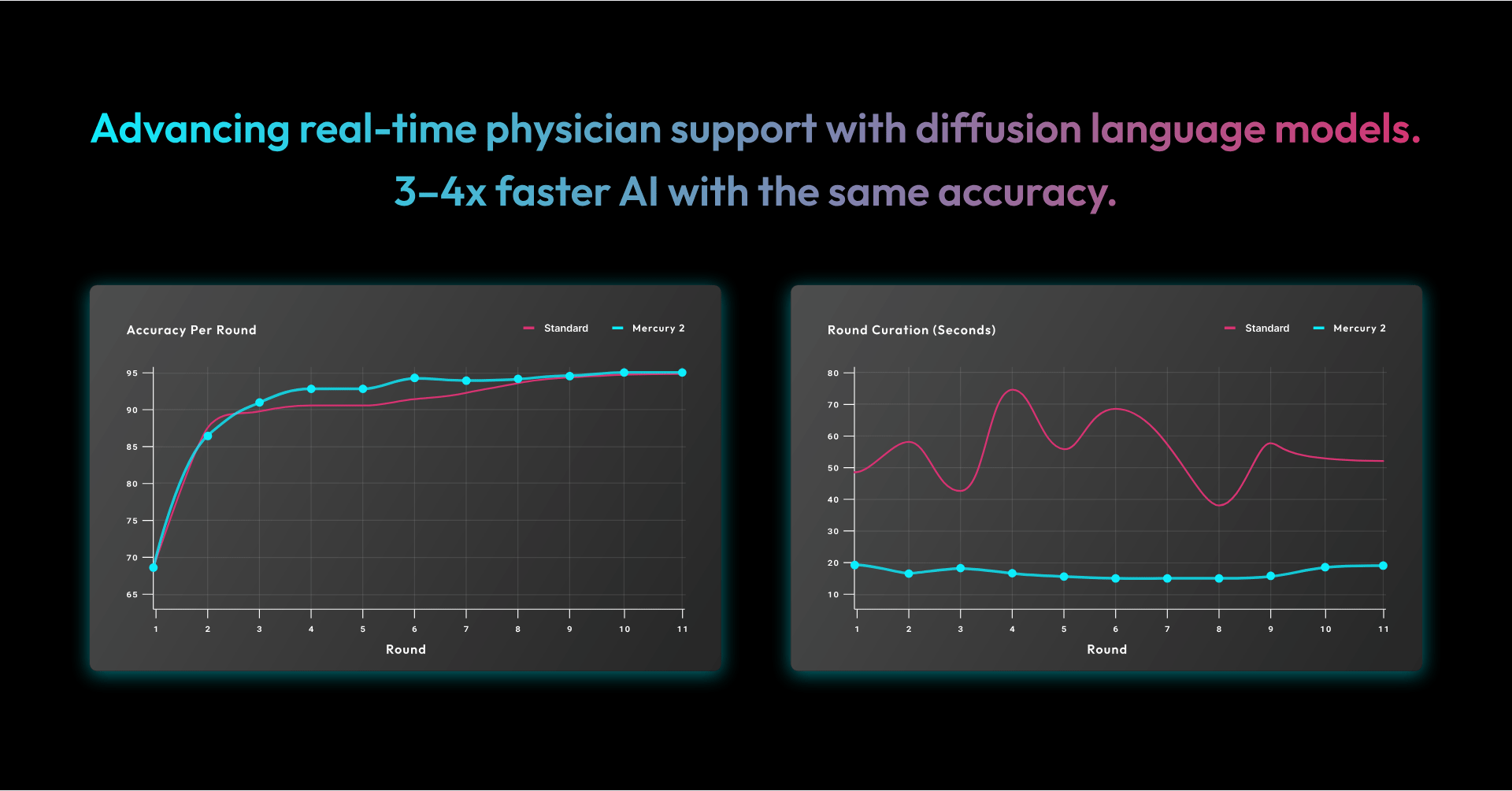
Processing time for training and reinforcement dropped from approximately 617 seconds to 168 seconds, while maintaining the same level of accuracy.
In practical terms, the system reached high-confidence answers much faster.
Importantly, these gains came without changing our core margin-optimized embeddings engine, demonstrating how new model architectures can accelerate existing production AI systems.
Why Diffusion Language Models Matter
Traditional large language models generate text one token at a time, which creates a built-in latency bottleneck. Diffusion language models take a different approach. Instead of decoding strictly sequentially, they generate and refine text through parallel denoising passes, allowing the model to update larger portions of an answer at once.
That architectural difference can significantly reduce latency while preserving output quality. More efficient decoding can translate into materially lower response times for production systems that rely on fast iteration, agentic workflows, and real-time responsiveness.
Diffusion models are already widely used in image generation, where they produce high-quality outputs by progressively refining noise into structured content. While these approaches have been explored in language modeling for several years, recent advances like Mercury-2 represent a meaningful step forward. The performance gains suggest diffusion-based architectures are becoming viable for real-time, production-grade language systems.
For AI platforms operating at scale, this efficiency matters. And in healthcare engagement, speed directly translates to better support for physicians.
Faster convergence means faster systems.
Faster systems unlock real-time capabilities.
And in healthcare engagement, real time makes all the difference.
What This Means for Physicians
Impiricus Ascend, our agentic delivery platform, was built to give physicians on-demand access to the clinical and pharmaceutical resources they need to care for patients through personalized Virtual Coordinators. These resources include:
- the latest clinical data and tools
- patient support information
- access and reimbursement programs
- educational materials from life science partners
- real time sample ordering
The challenge isn’t always the availability of those resources. It’s often the speed and precision of delivery. Community and rural physicians are historically underserved by traditional pharma field forces, while physicians in highly targeted urban markets face the opposite problem: hundreds of messages a day, most of which have nothing to do with the patient in front of them. Neither group is getting what they actually need.
Faster AI processing changes that dynamic. When complex queries resolve in seconds rather than minutes, virtual coordinators can respond in the moment, reducing friction in the physician workflow and giving clinicians the right answer before the window closes.
What This Means for Our Life Sciences Partners
For pharmaceutical and life science organizations, speed isn’t just a technical metric, it’s a commercial one. The brands that win physician attention are the ones that show up with the right resource at the right moment, not the ones that send the most messages.
These improvements in AI performance mean your brands can deliver on-demand support that integrates into the physician workflow rather than interrupting it. Requests get processed faster, relevant resources surface more efficiently, and engagement can scale across channels without sacrificing the relevance or quality that makes physicians actually respond. The goal is better and more moments of support.
Building the Future of Real-Time Physician Support
AI is evolving quickly, but not every advancement translates into real-world impact. At Impiricus, we evaluate new technologies based on a single question:
Does this help physicians access the resources they need to care for patients?
Our early experiments with diffusion language models suggest they play an important role in the next generation of healthcare AI systems.
We are grateful to the team at Inception Labs, especially Sid Sharma, for providing early access to Mercury-2 and enabling us to explore these capabilities.
This is only the beginning.
As AI continues to evolve, our focus remains the same: building intelligent systems that reduce noise, deliver meaningful support to physicians, and accelerate access to life-changing treatments.